Speech and Language Processing Laboratory
Industry Partner
- National Institute of Information and Communications Technology
- Edinburgh University
- Nagoya University
- National Institute of Informatics
- Tokyo Metropolitan University
- Techno-Speech, Inc.
Period
Since 1 Apr. 2017~
Until 31 Mar. 2022
Representative
Prof. Keiichi Tokuda
Members
- Prof. Keiichi Tokuda
- Prof. Lee Akinobu
- Assoc. Prof. Yoshihiko Nankaku
- Assoc. Prof. Daisuke Yamamoto
- Assoc. Prof. Shinji Sako
- Assoc. Prof. Kei Hashimoto
- Techno-Speech, Inc. Keiichiro Oura(Assoc. Prof. for project of NITech)
- Assoc.Prof. for project of NITech Shinji Takaki
- Prof. for project of NITech Naohisa Takahashi
- Prof. for project of NITech Hisashi Kawai (National Institute of Information and Communications Technology)
- Prof. for project of NITech Steve Renals (Edinburgh University)
- Prof. for project of NITech Simon King (Edinburgh University)
- Prof. for project of NITech Junichi Yamagishi (National Institute of Informatics)
- Prof. for project of NITech Tomoki Toda (Nagoya University)
- Assoc. Prof. for project of NITech Akira Tamamori (Aichi Institute of Technology)
- Assoc. Prof. for project of NITech Sayaka Shiota (Tokyo Metropolitan University)
- Assoc. Prof. for project of NITech Kazuhiro Nakamura (Techno-Speech, Inc.)
- Prof. for project of NITech Heiga Zen
- Assis. Prof. for project of NITech Kei Sawada (rinna Co,.Ltd.)
- Assis. Prof. for project of NITech Takenori Yoshimura (Nagoya University)
- Prof. for project of NITech Toramatsu Shintani
Theme
A framework for providing services using GPS information, biological data, and other types of information obtained constantly via mobile devices like smartphones and small devices connected to the Internet (called the Internet of Things (IoT)) has been growing rapidly in recent years. At the same time, the collection of information obtained from individual users and the analysis of that data in its entirety as statistical information is making it possible to acquire new information that could not be obtained from stand-alone data. This newfound information is being used to improve services and create new services on a nearly daily basis.
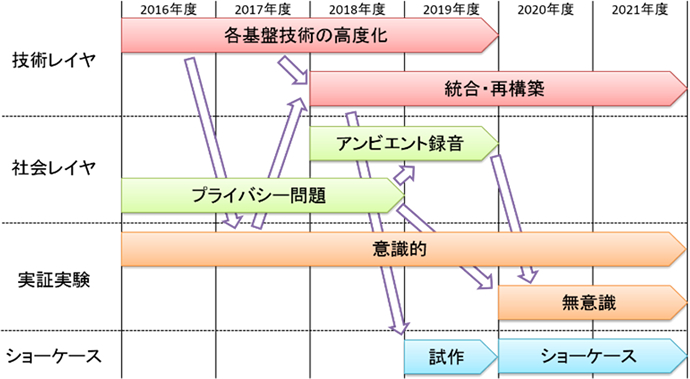
However, despite the fact that speech is the most basic means of conveying information for human beings, there are practically no trials being held at present on the continuous collection, integration, and use of speech. A major reason for this is user rejection due to privacy concerns. On the other hand, voice-search services such as Google Voice Search from Google Inc. are already be used to record speech when the user performs a voice search with the aim of improving system performance. Consequently, once the idea that "collecting and integrating voice data can lead to better services" circulates among users and the actual convenience of voice-based services overcomes their hesitance, we can expect the constant collection and integration of all kinds of voice data to become socially acceptable. Under these conditions, it is important that we waste no time in considering how to appropriately use continuously collected voice data and resolve privacy issues. The aim here is to turn a massive amount of continuously amassed voice data into a valuable asset for all of mankind.
Humans and machines always hold a sound environment in common, so the possibility arises of extracting not just text but various types of information from speech and of analyzing that information to identify diverse actions and phenomena of individuals and society. This should lead to the provision of totally new and diverse voice services such as "voice retouching" and "voice telescope" (see attachment, p. 8, "Research Plans and Execution," Showcase). In this research topic, we give the name "Super Auditory Human" to technology that exceeds the normal voice-information processing ability of humans. This technology will enable the optimal use of diverse types of voice data that are continuously being collected and integrated in large quantities in an "ambient sound environment." Our objective in achieving Super Auditory Human technology is to provide extensive support for human-to-human and human-to-machine voice communication and to dramatically enhance voice communication abilities in human intellectual activities.
Contact Us
| Address | (NITech) Keiichi Tokuda |
|---|